Tooling and Observability
CLI and API
- aether — 60+ CLI commands, batch and REPL modes
- aether-forge — local simulator with visual dashboard
- Management API — 60+ REST endpoints, WebSocket streams
- Passive Load Balancer — cluster-aware, smart routing, automatic failover
Built-in Observability
- Prometheus metrics (Micrometer)
- Per-method P50/P95/P99 tracking
- Dynamic tracing — toggle per method at runtime, no restart
- Dynamic log levels per logger at runtime
- Cluster event aggregator — 11 event types, WebSocket feed
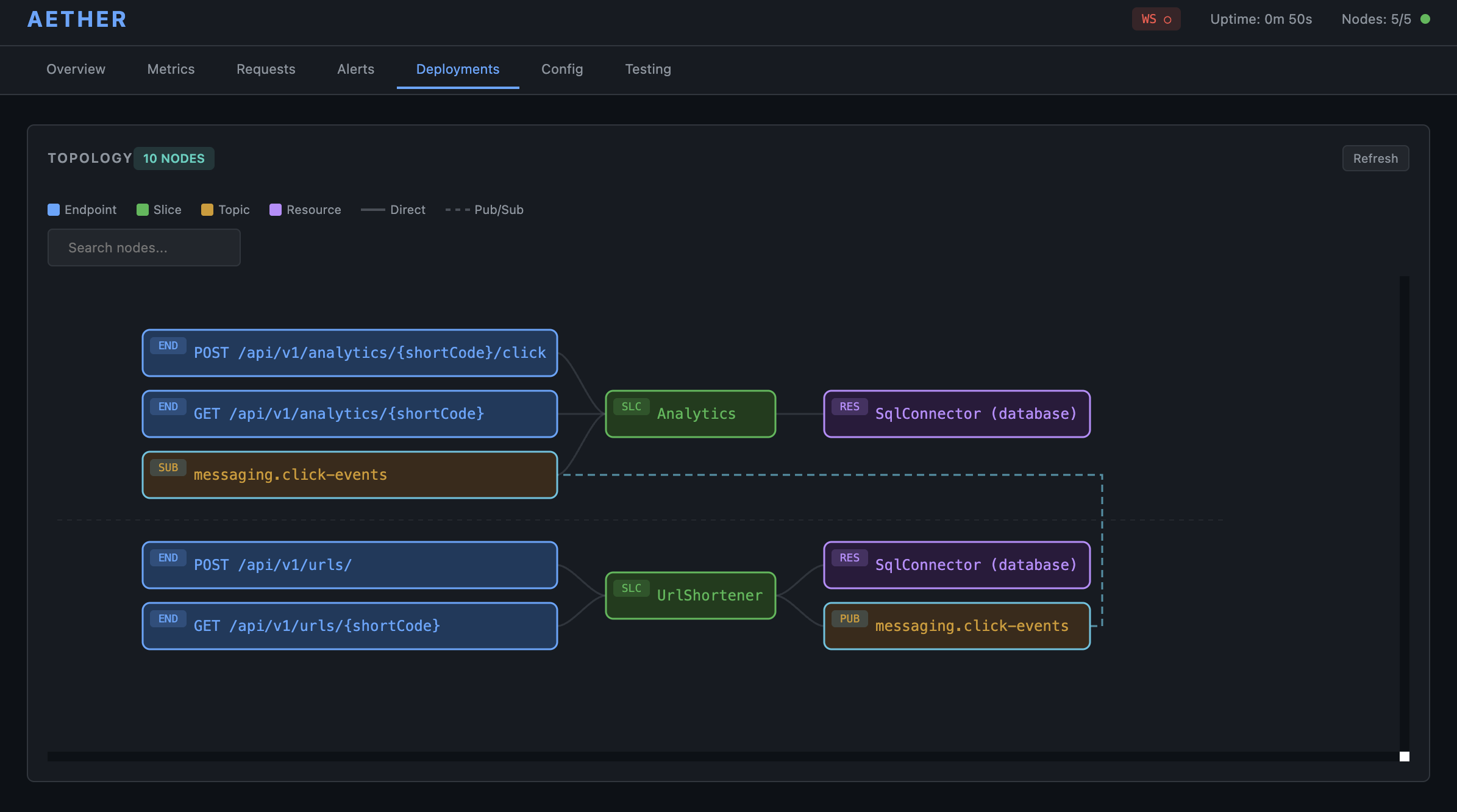
Topology Dashboard — compile-time data-flow graph with swim-lane layout, pub-sub routing, and search filtering.